| state | time | net | age | sex |
|---|---|---|---|---|
| VA | 5537 | 5305 | 45 | F |
| VA | 4426 | 4375 | 44 | M |
| VA | 4526 | 4480 | 48 | M |
2 Rectangular Data: Cases and Variables
The tendency of the casual mind is to pick out or stumble upon a sample which supports or defies its prejudices, and then to make it the representative of a whole class. – Walter Lippmann (1889-1974), journalist
The word “data” is plural. This is appropriate. Statistics is, at its heart, about variability: how things differ from one another.
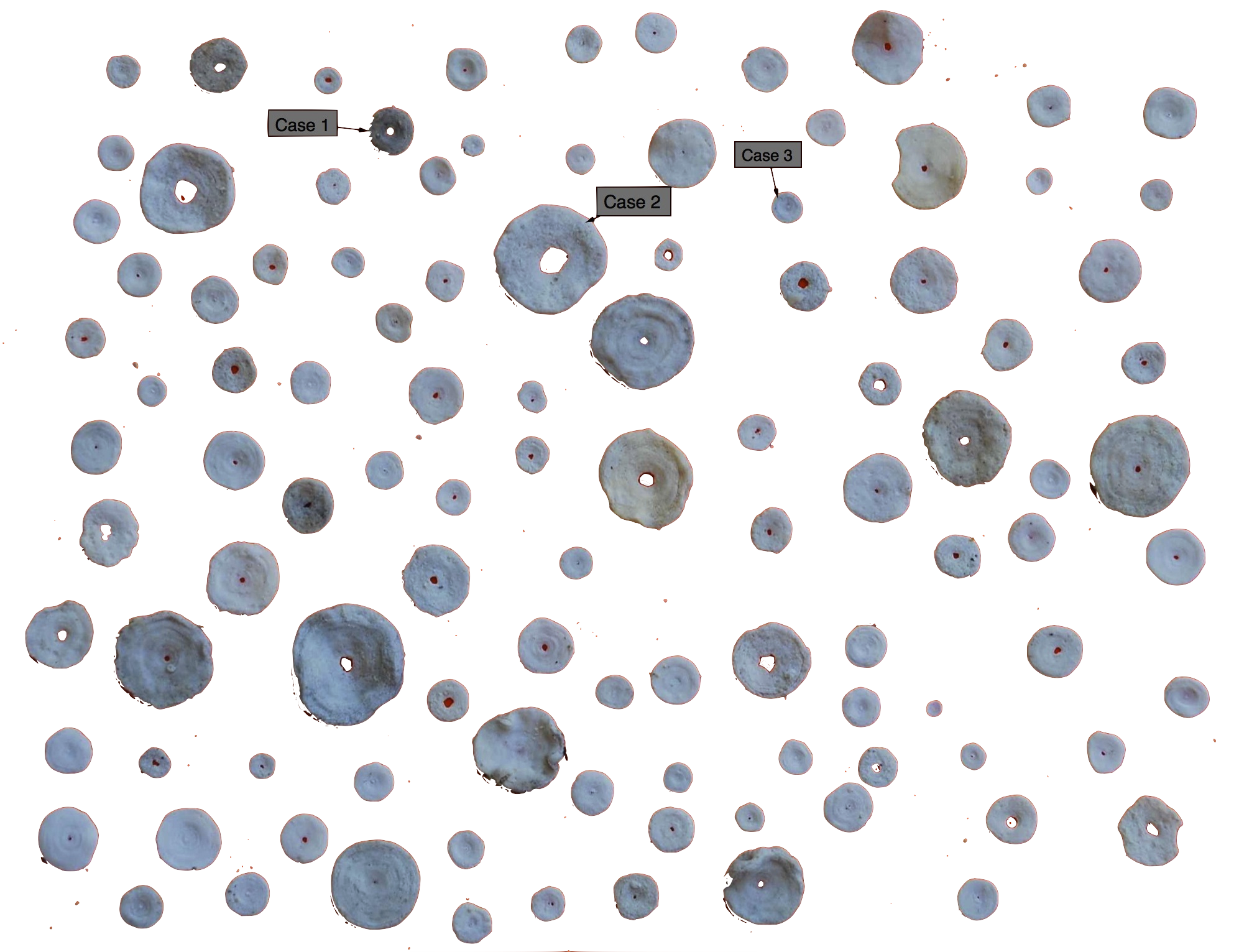
Figure 2.1 shows a small collection of sea shells gathered during an idle quarter hour sitting at one spot on the beach on Malololailai island in Fiji. All the shells in the collection are similar: small disk-shaped shells with a hole in the center. But the shells also differ from one another in overall size and weight, in color, in smoothness, in the size of the hole, etc.
Any data set is something like the shell collection. It consists of cases: the objects in the collection. Each case has one or more attributes or qualities, called variables. This word “variable” emphasizes that it is differences or variation that is often of primary interest.
Usually, there are many possible variables. The researcher chooses those that are of interest, often drawing on detailed knowledge of the system that is under study. The researcher measures or observes the value of each variable for each case. The result is a data table, also known as a data frame: a sort of spreadsheet. Within the data table, each row refers to one case, each column to one variable.
A data table for the sea shell collection might look like this:
| id | diameter | weight | color | hole |
|---|---|---|---|---|
| 1 | 4.3 | 0.010 | dark | medium |
| 2 | 12.0 | 0.050 | light | very large |
| 3 | 3.8 | 0.005 | light | none |
Each shell has a case number that identifies it; three of these are shown in the figure. These case numbers are arbitrary; the position of each case in the table – first, second, tenth, and so on – is of no significance. The point of assigning an identifying case number is just to make it easier to refer to individual cases later on.
If the data table had been a collection of people rather than shells, the person’s name or another identifying label could be used to identify the case.
Data organized with cases in rows and variables along columns can be called rectangular data. This is a very useful format for data, whether stored in a data frame, a spreadsheet or a relational database. It is the format we will encounter most often in this text. And for many operations on data, a useful first step is to put it into rectangular format, even if the “raw” data are organized some other way.
2.1 Kinds of Variables
Most people tend to think of data as numeric, but variables can also be descriptions, as the sea shell collection illustrates. The two basic types of data are:
Quantitative: Naturally represented by a number, for instance diameter, weight, temperature, age, and so on.
Categorical: A description that can be put simply into words or categories, for new customer vs. returning customer or red vs green vs yellow, and so on. The value for each case is selected from a fixed set of possibilities. This set of possibilities are the levels of the categorical variable.
Categorical variables show up in many different guises. For example, a data frame holding information about courses at a college might have a variable subject with levels biology, chemistry, dance, economics, and so on. The variable semester could have levels Fall2008, Spring2009, Fall2009, and so on. Even the instructor is a categorical variable. The instructor’s name or ID number could be used as the level of the variable.
Quantitative variables are numerical. Often they often have units attached to them. In the shell data frame, the variable diameter has been recorded in millimeters, while weight is given in milligrams. The usual practice is to treat quantitative variables as a pure number, without units being given explicitly. The information about the units – for instance that diameter is specified in millimeters – is often kept in a separate place called a code book.
The code book is a document that contains a short description of each variable and possibly some additional information about the study as a whole (how the cases were selected, who was involved in the data collections, etc.). For instance, the code book for the shell data might look like this:
Code book for shells from Malololailai island, collected on January 12, 2008.
diameter: the diameter of the disk in mm.weight: the shell weight in mg.color: a subjective description of the color.- Levels: light, medium, and dark.
hole: the size of the inner hole.- Levels: none, small, large, very large.
Sometimes quantitative information is represented by categorically as in the hole variable for the sea shells. For instance, a data frame holding a variable income might naturally be stored as a number in, say, dollars per year. Alternatively, the variable might be treated categorically with levels of, say, “less than $10,000 per year,” “between $10,000 and $20,000,” and so on. Almost always, the genuinely quantitative form is to be preferred. It conveys more information even if it is not correct to the last digit.
Note
Both quantitative and categorical variables can be described as simple variables because each consists of one number or a short text phrase for each case. One can also think of compound variables: an image is a set of many pixels, a color might be represented as a red/green/blue triplet of numbers, a location might be a latitude/longitude pair. This book considers only simple variables.
The distinction between quantitative and categorical data is essential, but there are other distinctions that can be helpful even if they are less important.
Some categorical variables have levels that have a natural order. For example, a categorical variable for temperature might have levels such as “cold,” “warm,” “hot,” “very hot.” Variables like this are called ordinal. Opinion surveys often ask for a choice from an ordinal scale such as this: strongly disagree, disagree, no opinion, agree, strongly agree. That is another ordinal scale.
Other categorical variables do not have a natural order. These are called nominal variables. The state in which a person lives, or their political party affiliation are examples of nominal variables. Sometimes whether a variable is nominal or ordinal is a matter of persepctive. Take color, for example. If we are recording favorite colors in survey, color is nominal. But to a physicist working with color along a spectrum, color may well be ordinal or even quantitative (measured by the frequency of light).
For the most part, this book will treat ordinal and nominal variables the same. But it’s worthwhile to pay attention to the natural ordering of an ordinal variable and there are statistical methods that explicitly take this into account. Indeed, sometimes it can be appropriate to treat an ordinal variable as if it were quantitative.
We can make finer distinctions among quantitative variables as well. These are less important for us. But you may see reference to things like ratio data and interval data. With interval data, differences are meaningful, but 0 might be placed arbitrarly on the scale. With ratio data, ratios are meaningful and 0 is not arbitrary.
Temperatures in degrees Fahrenheit or Celsius are a good illustration of interval data that is not ratio data. The two scales disagree about where 0 is, and if we double the temperature from 40 to 80 on the Fahrenheit scale, the ratio is different on the Celsius scale: 4.4 degrees to 26.7 degrees is a ratio of approximately 6! So is it twice as warm or 6 times as warm? The answer is that it is neither, we are working with an interval scale and ratios are not necessarily meaningful.
Beware of categorical variables that mascarade as numbers. If we put our subjects into three categories and label them 1, 2, and 3, that is still a categorical variable, even though we are using numbers. Similarly, ID numbers, ZIP codes, and telephone numbers are all categorical variables. We will see later that it can also useful to recode categorical variables as numbers in some of our models.
2.2 Data Frames and the Unit of Analysis
When collecting and organizing data, it’s important to be clear about what is a case. For the sea shells, this is pretty obvious; each individual shell is an individual case. But in many situations, it’s not so clear, or you may have a choice to make.
A key idea is the unit of analysis. Suppose, for instance, that you want to study the link between teacher pay, class size, and the performance of school children. There are all sorts of possibilities for how to analyze the data you collect. You might decide to compare different schools, looking at the average class size, average teacher pay, and average student performance in each school. Here, the unit of analysis is the school.
Or perhaps rather than averaging over all the classes in one school, you want to compare different classes, looking at the performance of the students in each class separately. The unit of analysis here is the class.
You might even decide to look at the performance of individual students, investigating how their performance is linked to the individual student’s family income or the education of the student’s parents. Perhaps even include the salary of student’s teacher, the size of the student’s class, and so on. The unit of analysis here is the individual student.
What’s the difference between a unit of analysis and a case? A case is a row in a data frame. In many studies, you need to bring together different data frames, each of which may have a different notion of case. Returning to the teacher’s pay example, one can easily imagine at least three different data frames being involved, with each frame storing data at a different level:
- A data frame with each class being a case and variables such as the size of the class, the school in which the class is taught, etc.
- A data frame with each teacher being a case and variables such as the teacher’s salary, years of experience, advanced training, etc.
- A data frame with each student being a case and variables such as the student’s test scores, the class that the student is in, and the student’s family income and parent education.
Once you choose the unit of analysis, you combine information from the different data frames to carry out the data analysis, generating a single data frame in which cases are your chosen unit of analysis. The choice of the unit of analysis can be determined by many things, such as the availability of data. As a general rule, it’s best to make the unit of analysis as small as possible. But there can be obstacles to doing this. You might find, for instance, that for privacy reasons (or less legitimate reasons of secrecy) the school district is unwilling to release the data at the individual student level, or even to release data on individual classes.
In the past, limitations in data analysis techniques and computational power provided a reason to use a coarse unit of analysis. Only a small amount of data could be handled effectively, so the unit of analysis was made large. For example, rather than using tens of thousand of individual students as the unit of analysis, a few dozen schools might be used instead. Nowadays these reasons are obsolete. The methods that will be covered in this book allow for a very fine unit of analysis. Standard personal computers have plenty of power to perform the required calculations.
2.3 Populations and Samples
A data frame is a collection, but a collection of what? Two important statistical terms are population and sample. A population is the set of all the possible objects or units which are of interest. The root of the word “population” refers to people, and often one works with data frames in which the cases are indeed individual people. The statistical concept is broader; one might have a population of sea shells, a population of houses, a population of events such as earthquakes or coin flips.
A sample is a selection of cases from the population.1 The sample size is the number of cases in the sample. In Figure 2.1, the sample size is n = 103.
A census is a sample that contains the entire population. The most familiar sort of census is the kind to count the people living in a country. The United States and the United Kingdom have a census every ten years. Countries such as Canada, Australia, and New Zealand hold a census every five years. Of course, these are not really a census in the statistical sense. Despite the best efforts of the census bereaus, no country is able to count everyone. A better example might be the data held by a business or university. They probably do have data about every customer, or transaction, or student. On the other hand, for a business, that might not be the population of interest. In the marketing department, for example, the population of interest includes people who are not (yet) customers. And the sales department may be interested in future purchases more than past purchases.
Almost always, the sample is just a small fraction of the population. There are good reasons for this. It can be expensive or damaging to take a sample: Imagine a biologist who tried to use all the laboratory rats in the world for his or her work! Still, when you draw a sample, it is generally because you are interested in finding out something about the population rather than just the sample at hand. That is, you want the sample to be genuinely representative of the population. (In some fields, the ability use a sample to draw conclusions that can be generalized is referred to as external validity or transferability.)
The process by which the sample is taken is important because it controls what sorts of conclusions can legitimately be drawn from the sample. One of the most important ideas of statistics is that a sample will be representative of the population if the sample is collected at random. In a simple random sample, each member of the population is equally likely to be included in the sample.
Ironically, taking a random sample, even from a single spot on the beach, requires organization and planning. The sea shells were collected haphazardly, but this is not a genuinely random sample. The bigger shells are much easier to see and pick up than the very small ones, so there is reason to think that the small shells are under-represented: the collection doesn’t have as big a proportion of them as in the population. To make the sample genuinely random, you need to have access in some way to the entire population so that you can pick any member with equal probability. For instance, if you want a sample of students at a particular university, you can get a list of all the students from the university registrar and use a computer to pick randomly from the list. Such a list of the entire set of possible cases is called a sampling frame.
In a sense, the sampling frame is the definition of the population for the purpose of drawing conclusions from the sample. For instance, a researcher studying cancer treatments might take the sampling frame to be the list of all the patients who visit a particular clinic in a specified month. A random sample from that sampling frame can reasonably be assumed to represent that particular population, but not necessarily the population of all cancer patients.
You should always be careful to define your sampling frame precisely. If you decide to sample university students by picking randomly from those who enter the front door of the library, you will get a sample that might not be typical for all university students. There’s nothing wrong with using the library students for your sample, but you need to be aware that your sample will be representative of just the library students, not necessarily all students.
When sampling at random, use formal random processes. For example, if you are sampling students who walk into the library, you can flip a coin to decide whether to include that student in your sample. When your sampling frame is in the form of a list, it’s wise to use a computer random number generator to select the cases to include in the sample.
A convenience sample is one where the sampling frame is defined mainly in a way that makes it easy for the researcher. For example, during lectures I often sample from the set of students in my class. These students – the ones who take statistics courses from me – are not necessarily representative of all university students. It might be fine to take a convenience sample in a quick, informal, preliminary study. But don’t make the mistake of assuming that the convenience sample is representative of any particular population. Even if you believe it yourself, how will you convince the people who are skeptical about your results?
When cases are selected in an informal way, it’s possible for the researcher to introduce a non-representativeness or sampling bias. For example, in deciding which students to interview who walk into the library, you might consciously or subconsciously select those who seem most approachable or who don’t seem to be in a hurry.
There are many possible sources of sampling bias. In surveys, sampling bias can come from non-response or self-selection. Perhaps some of the students who you selected randomly from the people entering the library have declined to participate in your survey. This non-response can make your sample non-representative. Or, perhaps some people who you didn’t pick at random have walked up to you to see what you are up to and want to be surveyed themselves. Such self-selected people are often different from people who you would pick at random.
In an example of self-selection bias, the newspaper columnist Ann Landers asked her readers, “If you had it to do over again, would you have children?” Over 70% of the respondents who wrote in said “No.” This result is utterly different from what was found in surveys on the same question done with a random sampling methodology: more than 90% said “Yes.” Presumably the people who bothered to write were people who had had a particularly bad experience as parents whereas the randomly selected parents are representative of the whole population. Or, as Ann Landers wrote, “[T]he hurt, angry, and disenchanted tend to write more readily than the contented ….” (See Bellhouse (2008).)
Non-response is often a factor in political polls, where people don’t like to express views that they think will be unpopular.
It’s hard to take a genuinely random sample. But if you don’t, you have no guarantee that your sample is representative. Do what you can to define your sampling frame precisely and to make your selections as randomly as possible from that frame. By using formal selection procedures (e.g., coin flips, computer random number generators) you have the opportunity to convince skeptics who might otherwise wonder what hidden biases were introduced by informal selections. If you believe that your imperfect selection may have introduced biases – for example the suspected under-representation of small shells in my collection – be up-front and honest about it. In surveys, you should keep track of the non-response rate and include that in whatever report you make of your study.
Good researchers take great effort to secure a random sample. One evening I received a phone call at home from the state health department. They were conducting a survey of access to health care, in particular how often people have illnesses for which they don’t get treatment. The person on the other end of the phone told me that they were dialing numbers randomly, checked to make sure that I live in the area of interest, and asked how many adults over age 18 live in the household. “Two,” I replied, “Me and my wife.” The researcher asked me to hold a minute while she generated a random number. Then the researcher asked to speak to my wife. “She isn’t home right now, but I’ll be happy to help you,” I offered. No deal.
The sampling frame was adults over age 18 who live in a particular area. Once the researcher had made a random selection, as she did after asking how many adults are in my household, she wasn’t going to accept any substitutes. It took three follow-up phone calls over a few days – at least that’s how many I answered, who knows how many I wasn’t home for – before the researcher was able to contact my wife. The researcher declined to interview me in order to avoid self-selection bias and worked hard to contact my wife – the randomly selected member of our household – in order to avoid non-response bias.
2.4 Longitudinal and Cross-Sectional Samples
Data are often collected to study the links between different traits. For example, the data in Table 2.1 are a small part of a larger data set of the speeds of runners in a ten-mile race held in Washington, D.C. in 2008. The variable time gives the time from the start gun to the finish line, in seconds.
Such data might be used to study the link between age and speed, for example to find out at what age people run the fastest and how much they slow down as they age beyond that.
This sample is a cross section, a snapshot of the population that includes people of different ages. Each person is included only once.
Another type of sample is longitudinal, where the cases are tracked over time, each person being included more than once in the data frame. Table 2.3 shows a small part of longitudinal data set for the runners. The individual runners have been tracked from year to year, so each individual person shows up in multiple rows.
| ID | year | age | sex | net | gun | nruns |
|---|---|---|---|---|---|---|
| R1 | 2003 | 37 | F | 100.13333 | 103.30000 | 2 |
| R1 | 2008 | 42 | F | NA | 112.36667 | 2 |
| R2 | 2005 | 14 | F | 89.36667 | 94.36667 | 2 |
| R2 | 2006 | 15 | F | 71.21667 | 74.83333 | 2 |
| R3 | 2005 | 31 | M | 85.35000 | 86.88333 | 4 |
| R3 | 2006 | 32 | M | 91.75000 | 92.53333 | 4 |
If your concern is to understand how individual change as they age, it’s best to collect data that show such change in individuals. Using cross-sectional data to study a longitudinal problem is risky. Suppose, as seems likely, that younger runners who are slow tend to drop out of racing as they age, so the older runners who do participate are those who tend to be faster. This could bias your estimate of how running speed changes with age.
2.5 Reading Questions
What are the two major different kinds of variables?
How are variables and cases arranged in rectangular data?
What the relationship among these terms: population, sample, sampling frame, census?
What is the difference between longitudinal and cross-sectional data?
This definition is not quite correct. The set of all possible cases for a sample is called the sampling frame. Ideally the sampling frame and population are the same. The problem is that it can sometimes be difficult to determine whether a potential case is part of the population. Or some cases in the population may difficult or impossible to sample. Perhaps you have seen polls of “likely voters” ahead of an election. In this situation, the population is all voters in an upcoming election. But we don’t know in advance who those people will be. Pollsters use additional questions to determine whether someone is a likely voter. But not all likely voters vote, and some unlikely voters do. So there is a mismatch between the sampling frame and the population. One of the primary challenges of election polling is to determine likely voters in a way that will end up reflecting actual voters.
For the most part, we will ignore this (sometimes crucually important) subtelty and speak as if the sample is a subset of the population, even when this might not technically be the case.↩︎